HOMEWORK 7
 Direct WU-BLAST submission
at EMBNet-CH(Lausanne,Switzerland)
Direct WU-BLAST submission
at EMBNet-CH(Lausanne,Switzerland)
 Sequence analysis tool:Protparam
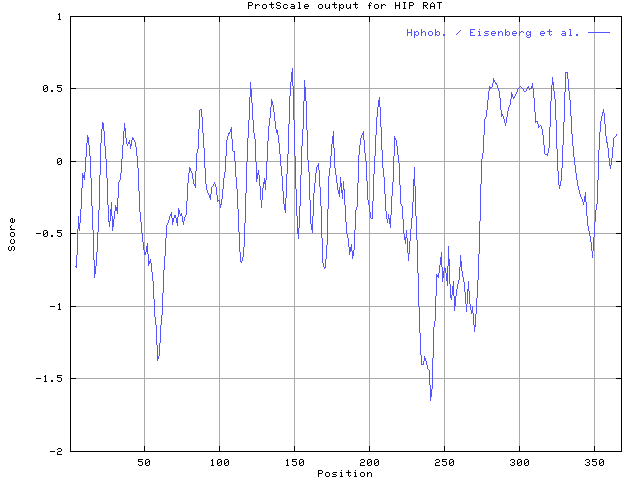
Sequence analysis tool:ProtScale¡
Sequence analysis tool:Protparam
Sequence analysis tool:ProtScale¡
Ala: 0.620 Arg: -2.530 Asn: -0.780 Asp: -0.900
Cys: 0.290 Gln: -0.850
Glu: -0.740 Gly: 0.480 His: -0.400 Ile: 1.380
Leu: 1.060 Lys: -1.500
Met: 0.640 Phe: 1.190 Pro: 0.120 Ser:
-0.180 Thr: -0.050 Trp: 0.810
Tyr: 0.260 Val: 1.080 Asx: -0.840 Glx: -0.795
Xaa: -0.000
Weights for window positions 1,..,7, using linear weight variation model:
1 2
3 4
5 6
7
0.40 0.60 0.80 1.00 0.80 0.60 0.40
edge
center
edge
HSC70-INTERACTING PROTEIN.
RATTUS NORVEGICUS (RAT).
[1]
PDOC00001 PS00001
ASN_GLYCOSYLATION
N-glycosylation site
343-346 NMSK
[2] PDOC00004
PS00004
CAMP_PHOSPHO_SITE
cAMP- and cGMP-dependent protein kinase phosphorylation site
Number of matches: 3
1 4-7 RKVS
2 152-155 KRAS
3 270-273 RRQS
[3] PDOC00005
PS00005
PKC_PHOSPHO_SITE
Protein kinase C phosphorylation site
Number of matches: 2
1 46-48 THK
2 361-363 SAK
[4] PDOC00006
PS00006
CK2_PHOSPHO_SITE
Casein kinase II phosphorylation site
Number of matches: 5
1 55-58 TKEE
2 63-66 TTED
3 74-77 SSEE
4 78-81 SDLE
5 317-320 SDPE
[5] PDOC00008
PS00008
MYRISTYL
N-myristoylation site
Number of matches: 10
1 86-91 GVIEAD
2 274-279 GSQFGS
3 278-283 GSFPGG
4 282-287 GGFPGG
5 286-291 GGMPGN
6 287-292 GMPGNF
7 290-295 GNFPGG
8 294-299 GGMPGM
9 298-303 GMGGAM
10 301-306 GAMPGM
¡C Protein
Colourer - Tool for colouring your amino acid sequence
¬d¸ßµ²ªG¡G
AGILPV-ÂŦâ
FYW-¬õ¦â
DENQRHISIK-ºñ¦â
CM-¶À¦â
