5.4.2 Hierarchical Clustering Analysis Dialog
Function:
To seek a clustering based on distance between points in the Euclidean space, with results available as a dendrogram showing the hierarchy of clusters at increasing level of detail.
License Requirements:
This application requires a QSAR license ("QSAR").
Menubar:
MSS: QSAR >>> Hierarchical Clustering...
or select the Reanalyze QSAR item when a hierarchical clustering analysis is currently selected. When you select Reanalyze QSAR, initial values will be those used in the currently selected analysis.
Dialog Description:
Figure 30 Hierarchical Clustering Analysis dialog
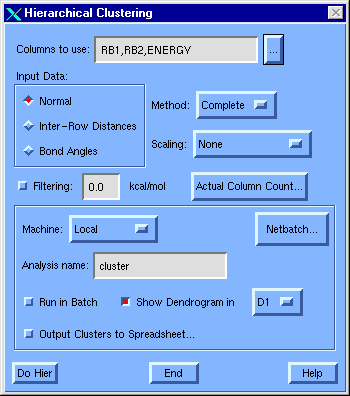
Columns to use [field and push button]
In the field specify the column(s) to use for this analysis. If columns are preselected in the spreadsheet their column names are listed here when you open the dialog, if they fit in the field; if the names are too long, a list of column numbers is shown instead. You can use column numbers, expressions (e.g., 3:5) or minimal unambiguous names when entering or changing column selections.
Push the [...] to access the Column Selection Dialog (see the Molecular Spreadsheet Manual). Use it to select the desired column from a list of column names for column types (INT, EXPLICIT, DOUBLE, FINGERPRINT, and COMFA) which can be used for hierarchical analysis.
Input Data
Normal [radio button]
Select this radio button when the input data are ordinary data values.
Inter-Row Distances [radio button]
Select this radio button when the input data cells contain distances among rows. The data matrix must then be diagonally symmetric.
Bond Angles [radio button]
Select this radio button when the input data are torsional angles, such that a value of 359 is as close to 5 as it is to 353.
Parameters
Method [option menu]
Select a method to be used to evaluate distances between clusters: Single, Average, Complete, Median. The difference between methods is in how distances between clusters are calculated.
- Single takes the distance between two clusters to be the smallest distance between their constituent points, producing dendrograms in which singletons sequentially coalesce into the first-formed cluster.
- Complete takes the inter-cluster distance to be the greatest separation between their elements, producing dendrograms with multiple, compact root clusters and minimizing the generation of singletons.
- Average is an intermediate which uses the average of all pairwise distances between points in two clusters
- Median takes the distances between points within clusters into consideration.
Scaling [option menu]
Select an option to control the relative weights for individual columns in the hierarchical clustering analysis.
- Autoscale Centers each variable and rescales to unit variance. Recommended if no CoMFA columns are involved in the analysis. Uses this as the default if no CoMFA column has been selected.
- CoMFA Standard Scales fields as if they were single variables to prevent scalar variables from being overwhelmed. Recommended if any CoMFA columns have been selected.
- Specify Writes the CoMFA Standard weights for each variable and field to the terminal window for you to modify.
- None No weighting; emphasizes variables with a larger numerical spread.
Filtering [check box and field]
Note: Only CoMFA columns are affected by this operation. It is usually best to leave filtering OFF for hierarchical analyses or to set the threshold as low as possible. In particular, column filtering is generally inappropriate and unnecessary when H-bond or Indicator CoMFA fields are involved.
Check the box to omit from the hierarchical clustering analysis those descriptor columns (lattice points) whose energy variation is less than the value indicated in the Filtering text field. Applying column filtering speeds up the calculations, though not nearly so much as for PLS.
In the field, enter the minimum value of energy variation a CoMFA lattice point must have to be included in the hierarchical clustering analysis.
Actual Column Count... [push button]
Press this button to calculate the number of descriptors columns which would be dropped (if any), as well as number of columns which would be used if the analysis were performed with the current dialog settings. The values obtained are written in the textport window.
You may use this button in conjunction with the Filtering field to choose the minimum variance required for a descriptors to be included in the analysis.
Note: A single CoMFA table column typically corresponds to hundreds or thousands of actual columns, one for each lattice point in the field it represents (see Building Spreadsheet for CoMFA for further discussion).
Batch Settings
Machine [option menu]
Select from this menu the machine to be used for a hierarchical clustering batch run: Local or another machine on your network.
Analysis name [field]
Enter the name of the analysis. It will be used for future reference and for any batch job.
Netbatch [push button]
Run in Batch [check box]
Check this box to perform the analysis in batch mode rather than in interactive mode.
Show Dendrogram [check box and option menu]
Check the box to create a dendrogram for the new analysis before you are prompted whether or not to save it permanently. The menu is (re)set by default to a display area which does not already contain a graph, or to D1 if graphs are posted in all four display areas. It does not check for occupancy of the corresponding molecule areas.
By setting your screen to quartered mode, you can compare your results with existing hierarchical analyses to help decide whether or not to keep the new analysis. If you opt to not save the analysis, the dendrogram will be deleted.
Output Clusters to Spreadsheet [check box]
Check this box to automatically invoke the Generate Cluster Column(s) Dialog after the analysis is complete. This allows for the interactive creation of cluster columns derived from the hierarchical analysis produced and allows retention of the analysis file.
When this check box is off, analysis output is controlled by TAILOR SET QSAR_ANALYSIS ANALYSIS_OUTPUT; a setting of NORMAL_FILE leads to the generation of a regular hierarchical analysis file, whereas a setting of COLUMN_ONLY results in creation of a cluster column at the level dictated by the value of TAILOR SET HIER LEVEL_FOR_COLUMNS, with no analysis file being retained.
Note: Interactive cluster column output requires an Advanced CoMFA license.
Additional Information:

Copyright © 1999, Tripos Inc. All rights
reserved.





